1 视图
设置的别名
create view as + SQL语句
用别名代表临时表
2 触发器
对某张表增删改时,使用触发器自定义关联表,这个是数据级别的自动操作
所谓的前后是用C语言写的装饰器,这中间先解析
new :insert 有
old :delete
updata 都有
3 函数
内置函数:
聚合函数
select curdate();– 获得当前时间
字符串
时间类
格式化时间 DATE_FORMAT(时间,“%”)
自定义函数:
123456789101112131415
delimeter \\ -- 修改结束符create functionf1( i1 int, i1 int )begin declare num int default 0; -- 声明变量 set num = i1+i2; retuen(num);end \\ -- 结束return int -- 返回值必须int delimeter ; --还要改回来
函数调用
select f1(1,100);
自定义函数的关键是:有返回值
内部不能执行SQL
4 存储过程
很重要
是保存在MySQL上的别名,是一坨SQL语句
别名
用于替代写SQL
delimiter //
create procedure p1()
begin
select
insert into
end //
delimiter ;
调用
call p1();
客户端socket发送仅仅发送 p1就行了
但是实际的是看公司的情况DBA
方式一:
MySQL:存储过程
程序:调用存储过程
方式二:
mysql:
程序:SQL语句
方式三:
程序:类和对象(SQL语句)
pymysql
cursor.callproc(‘p1’)
传参数
关键字 in out inout
创建session级别的变量
set @v1 =0;
存储过程总结:
可传参数
没有return 通过out获得
使用pyMySQL想要获得out的返回值的,还要查询一遍
游标
在每一行需要分门别类的时候需要
|
|
执行 call p6();
动态执行SQL 防止SQL注入
5 索引
查看索引
show index from table名;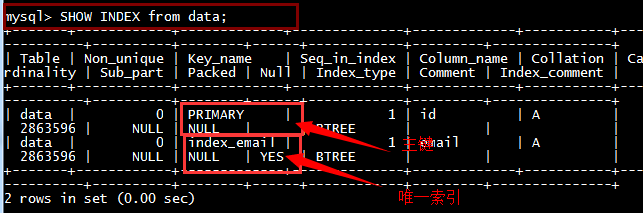
索引的作用是约束和加速查找,通过对比在300万条数据中的查找通过索引查找的速度明显快于没有索引的
python生成300万条数据
前提是首先创建数据库和数据表,表的名字是data.sql
通过数据库导入即可
5.1 索引的分类
- 主键索引 :加速查找+不能为空+不能重复
- 普通索引 :加速查找
- 唯一索引 :加速查找,不能重复
- 联合索引(多列)
- 联合主键
- 联合普通
- 联合唯一
5.2 索引实际就是创建额外的数据格式
可以把索引看做是字典的索引,前期制作需要长的时间,但是之后查询的时间就会很快
制作索引的时间: 37.616s
创建索引后的查询时间是0.148s
5.3 索引的种类
hash索引
这个适合查找单值
不适合查找范围
把name转换成哈希值,查找的时候直接就对应这个btree索引
二叉树
在MySQL中的应用最广
二叉树,左边数字小,右边数字大,也是把name转换成相应的数字,查找的时候是按照层查找,如1024个数字,仅仅通过10层就可以查找到,是2的n次方的关系。
索引的建立
- 建立索引需要建立额外的数据结构
- 但是插入数据慢(就如同在字典的索引中进行添加)
5.4 命中索引
命中索引的意思是用到了索引,结果是查询速度快
|
|
可以看到下面的type类型,第一个是ref,这个是命中索引,第二个是进行了全局搜索,没有命中索引

5.4.1 主键索引
- 惟一地标识一行 ,不能为空
- 作为一个可以被外键有效引用的对象。
5.4.2 普通索引
普通索引没有任何限制
- 创建:create index 索引名 on table名(列名);
- 删除:drop index +索引名 on table名;
5.4.3 唯一索引
唯一索引和普通索引类似,但是不同的而是,索引值必须唯一,但是允许有空值。
如果是组合索引,则列值的组合必须唯一
- 创建:create unique index 索引名 on table名(列名);
- 删除:drop index +索引名 on table名;
注意的是删除的时候不用加unique
5.4.4 组合索引(最左前缀匹配原则)
|
|

下面就是最左分配原则
证明
从下面可以看出最后的是ALL,是从数据库的整体进行搜索。
5.4.5 索引的两个名词
覆盖索引
覆盖索引是指从创建的“索引文件”(btree或者hash)中直接获取数据
如创建了name的普通索引1SELECT name from data WHERE NAME='aaa9999';--这个句式覆盖索引
- 索引合并
索引合并是把多个单列索引合并使用
如分别创建了name,email两个索引1SELECT * from data WHERE NAME='aaa9999' and email='aaa9999@xx.com'
5.4.6 区别组合索引 和索引合并
首先,组合索引的效率高于索引合并
组合索引:
- (name,email,)
索引合并:
- name
- email
5.5 实际中是频繁查找的列创建索引
虽然创建了索引,但是实际在查询中关键是命中索引,最直接的现象就是查询速度慢,这个通过慢日志进行查询。
没有命中索引的特殊情况:
like ‘%xx’ 模糊查询
select * from tb1 where email like ‘%cn’;
使用函数
select * from tb1 where reverse(email) = ‘abc’;
如1explaint SELECT * from data where REVERSE(email)='aaa222@xx.com'结果中:type是all,所以是没有命中索引
or
下面的情况只有id有索引,name没有索引,会全局搜索
1SELECT * from `data` WHERE id= 10000 or name ='aaa999@xx.com'这个ID是索引 name不是索引的时候,遇见or,索引就不会命中,而且获得的内容是第一个
特殊情况:在or中可以命中索引的情况
这种情况是id和name都是索引1SELECT * from `data` WHERE id= 10000 or name ='aaa999@xx.com'1SELECT * from `data` WHERE id= 10000 or email='aaa888@xx.com' and name ='aaa999@xx.com' -- name 是索引 **这时查询的结果是第一个id的**
类型不一致
如果列是字符串类型,传入条件是必须用引号引起来
!=
1SELECT * from data WHERE name!='aaa999'--不会命中索引但是主键依然会走索引,但是数据特别大的话,查询的还是很慢的
>
1select * from tb1 where email > 'aaa'特殊情况
如果是主键或索引是整数类型,则还是会走索引,在数据量很大的情况是查询也是很慢的12elect * from tb1 where nid > 123select * from tb1 where num > 123
order by
1SELECT name from data ORDER BY name desc;--这种消耗 了410秒组合索引最左前缀
看上面5.4.4的内容
5.6 MySQL执行预估操作
关于命中索引的情况:
在SQL语句前面加上explain ,看返回的type
all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
type:: all 代表全表扫描
type:congst代表索引
5.7 慢日志
针对在前面的未命中索引的情况,导致的结果是SQL语句的执行效率低,运行时间长,DBA通过开启慢日志查看然后进行优化
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10S以上的语句。默认情况下,Mysql数据库并不启动慢查询日志,需要我们手动来设置这个参数,当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
配置
内存
show variables like ‘%slow_query_log%’;
默认是OFF,通过set global slow_query_log=1;

配置文件(修改my.cnf文件)
mysqld –defaults-file=’E:\mysql-5.7.16-winx64\mysql-5.7.16-winx64\my-default.ini’
my.conf内容:- slow_query_log = ON
- slow_query_log_file = D:/….
修改后需要重启服务
使用set global slow_query_log=1开启了慢查询日志只对当前数据库生效,如果MySQL重启后则会失效。如果要永久生效,就必须修改配置文件my.cnf(其它系统变量也是如此)
5.8 分页操作
分页的情况有有简单的,有最优化的,看博客园分页,并没有把全部的展现,最多显示200页。
在索引表中扫描
1SELECT B.id from (SELECT id from `data` LIMIT 200000,10) as B;--limit不能放在子查询中,需要设置临时表最优方案(记录当前页面的最大最小ID)
页面只有上一页,下一页
下一页
记录当前页面的最大ID,这里设置成了2001SELECT * from data WHERE id>200 LIMIT 10上一页
这里记录了当前页面的最小ID
123SELECT * from data WHERE id<200 ORDER BY id DESC limit 10;--通过order by desc 倒序排序SELECT B.id,B.name,B.email FROM(SELECT * from data WHERE id<200 ORDER BY id DESC limit 10)as B ORDER BY B.id ;--对其排序上下页之间有页码选择
如:上一页 192 193 [196] 197 198 199 下一页
注意:id不一定是连续的,中间的记录有可能删除,所以在不能用between and的范围进行查找
6 ORM 操作
ORM 对象-关系-映射
参考内容:
http://www.cnblogs.com/wupeiqi/articles/5716963.html
http://www.cnblogs.com/aquilahkj/archive/2011/11/07/2240310.html
http://www.cnblogs.com/stevenchen2016/p/5770214.html
http://www.cnblogs.com/wupeiqi/articles/5713330.html